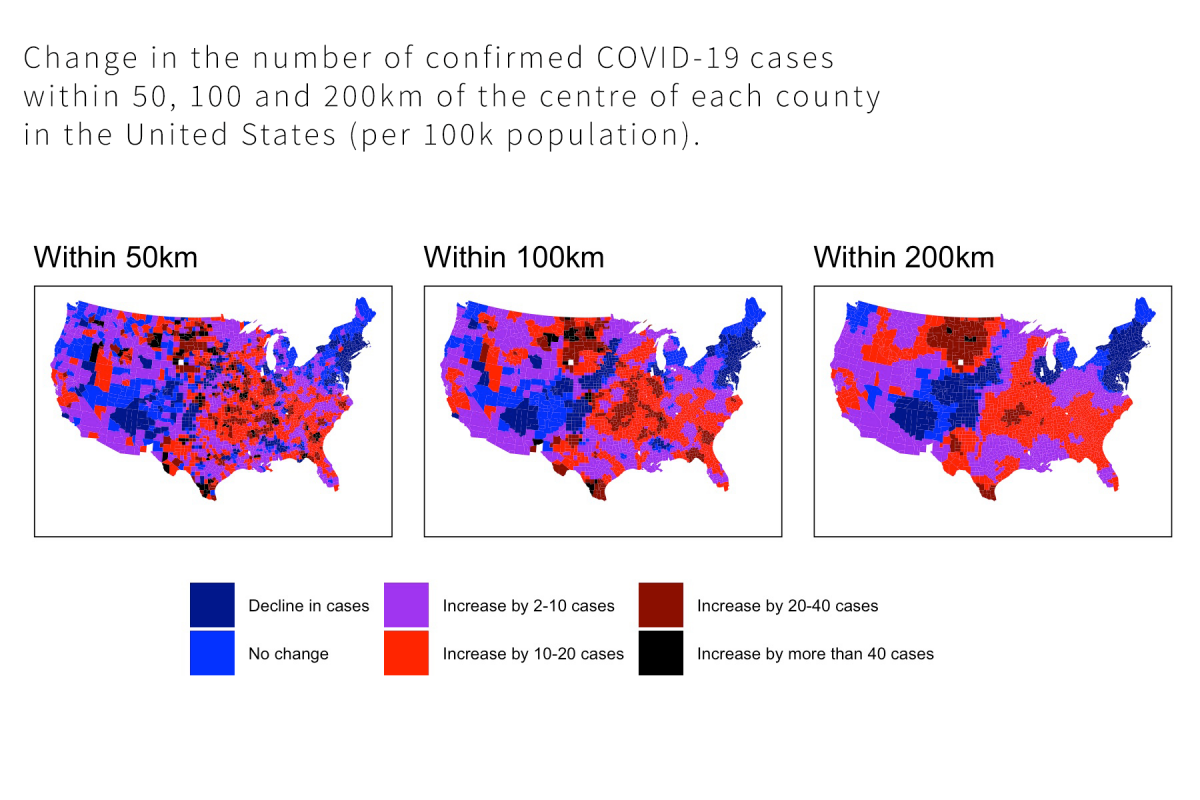
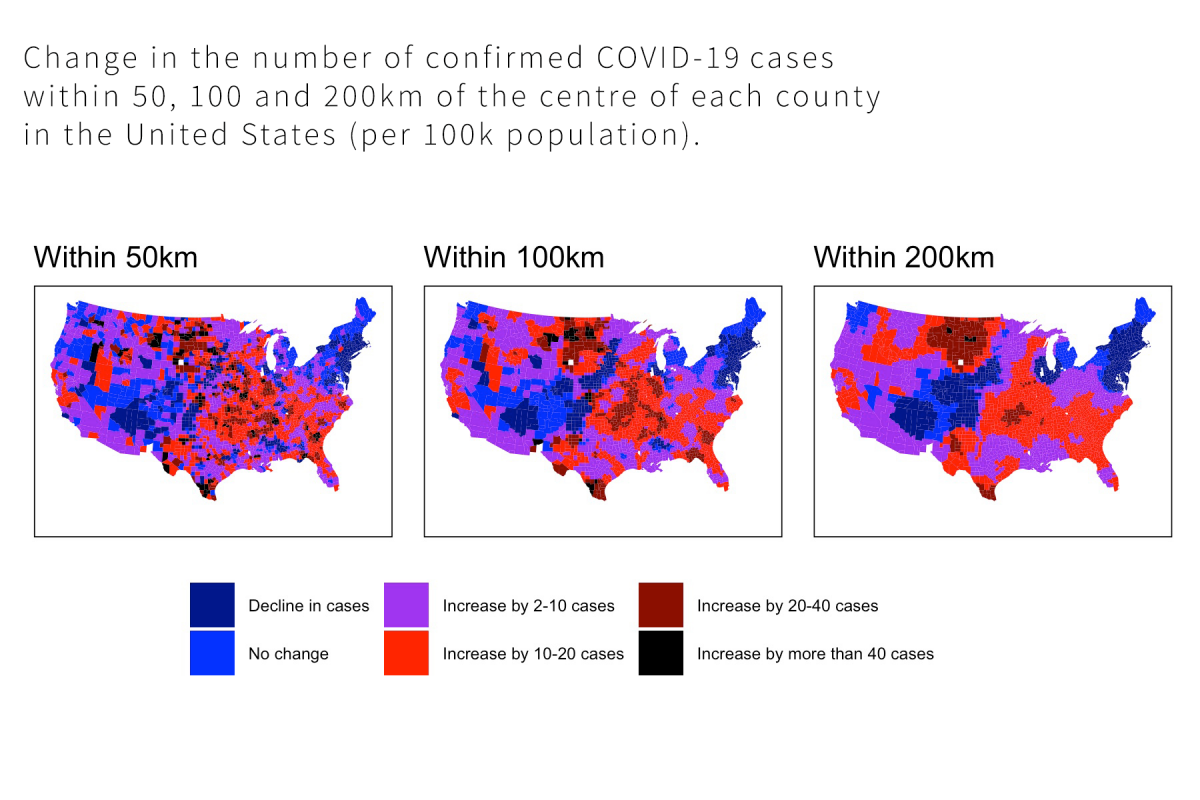
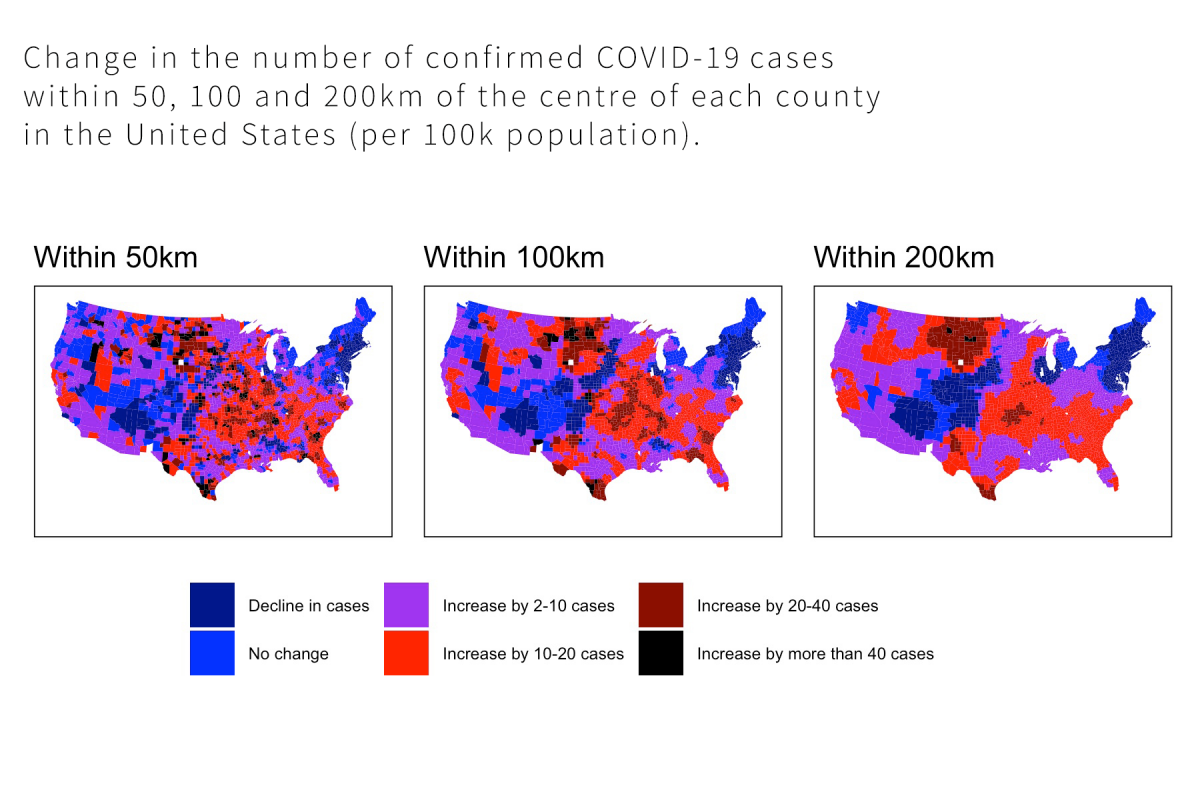
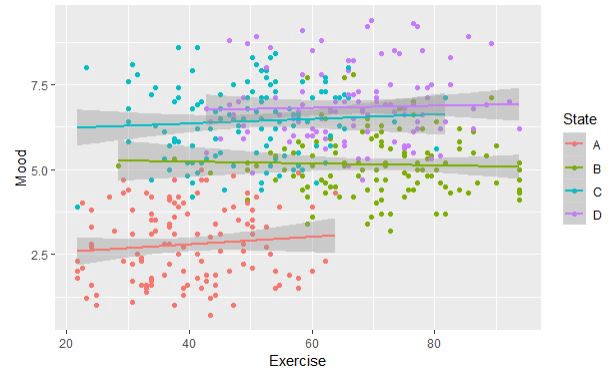
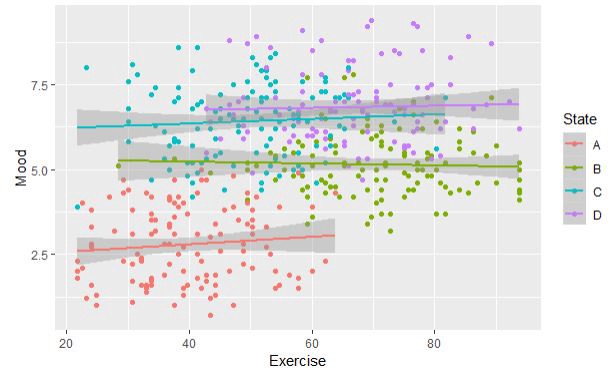
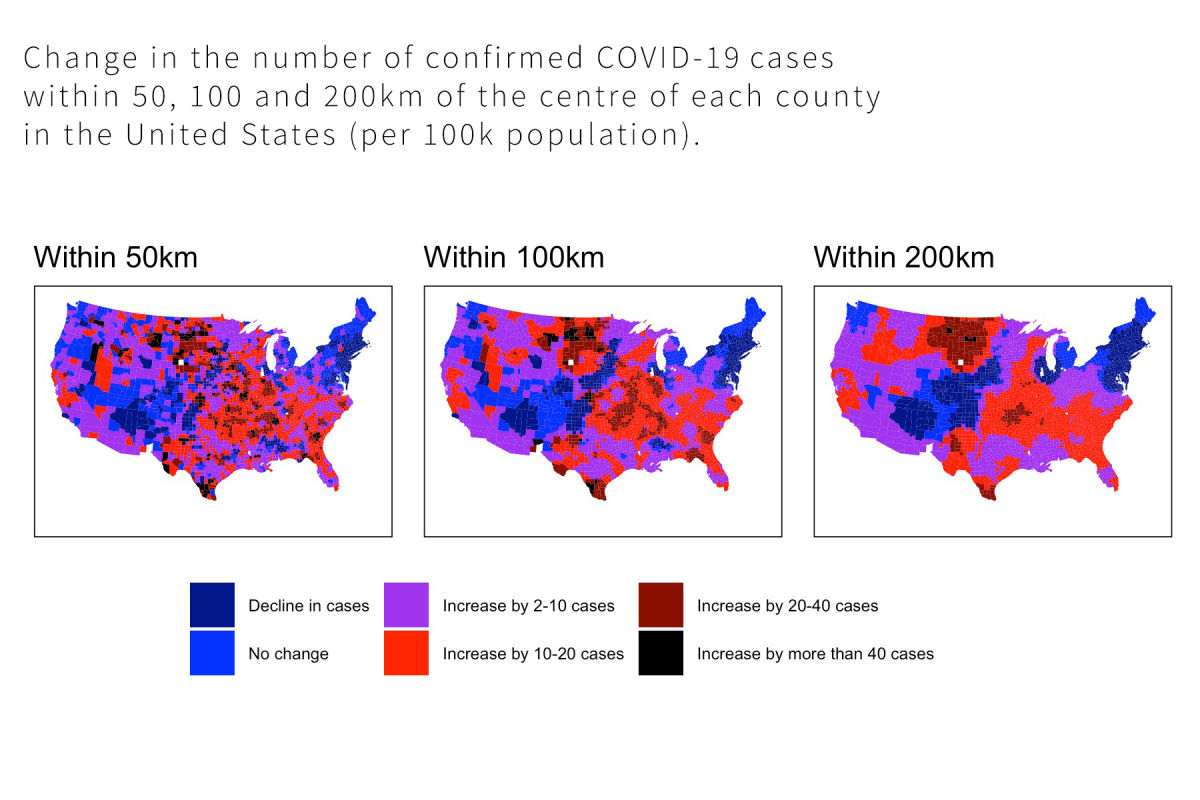
In this course you will learn about all elements of the qualitative research process and how they are interrelated. We will unpack the key components of qualitative research design, including the stances and theories that underpin qualitative methodologies, as well as techniques of data collection and analysis. We pay particular attention to what’s involved in ethically employing popular methods such as interviewing and observation. The course combines lectures covering foundational issues with practical workshops that give you a chance to practice qualitative techniques first-hand.
The target audience for this course is those who would like to become more familiar with qualitative research techniques, from postgraduate university students and staff to researchers in government and private organisations.
- Teacher: Emma Mitchell